AWS SageMaker 1 : SageMaker 개요 및 ML 솔루션 동향
1. SageMaker 개요

고성능의 저장장치, 급성장한 IT인프라, 방대한 소비자 데이터가 수 십 년간 쌓이면서 빅데이터가 형성되었고 데이터분석 및 시각화와 AI기술이 몇 년간 급성장하고 있다. 특히 머신러닝 기술은 기본적으로 빅데이터를 재료로 삼아 기계가 인간처럼 자연스럽게 판단하는 기술이기에 고성능 컴퓨팅 기술과 장비는 물론이고 데이터 정제화와 모델링 기술이 중요해졌다. 하지만 데이터는 밀리초마다 예측 불가능하게 쏟아져 레거시 시스템 구축에 대한 비용예측이 어렵고 데이터 분석가 및 사이언티스트의 인력은 한정적이기 때문에 제한된 기업과 사용자만이 머신러닝, 딥러닝 기술을 이용한 서비스 배포를 할 수 있었다.
그렇기에 예측불가능한 데이터를 감당해 낼 수있는 탄력적으로 운용 가능한 고성능 컴퓨팅 기술이 필요했고 모델링 훈련 배포를 정확하고 간편한 과정과 비용절감 및 효율성을 높여줄 클라우드 기술이 필요했다. 이러한 현상에 긍정적인 효과를 넣어줄 서비스가 바로 SageMaker이다. SageMaker는 데이터 사이언티스트와 비즈니스 분석가를 위해 머신러닝 모델 구축 및 훈련 배포를 담당하는 완전관리형 서비스이다. 클라우드 인프라로 전환을 하는 시점인 현재 ML 솔루션에 도전할 수 있는 발판을 만들어주고 있는 AWS서비스이다.
- 클라우드 AI 개발자 서비스에 대한 Magic Quadrant

클라우드 기반 AI 개발자 서비스에 관해 Gartner는 SageMaker에 대해 AWS의 AI 운영 및 생산 확장성이 뛰어나다고 평가했고 자연어 처리 분석을 담당하는 AWS Comprehend, 시계열 예측 서비스인 AWS Forecast, 챗봇 서비스인 AWS Lex, 이미지와 비디오에 대한 딥러닝을 담당하는 AWS Rekognition와 같은 AI 서비스와 함께 2022년 "Ability to Execute" 부문에서 1등을 한 모습을 확인할 수 있다.
2. SageMaker 구성요소

1) Getting started
- Studio, Studio Lab


- studio는 ide를 통해 기계학습을 할 수있고 사용한 만큼 비용을 지불해야한다. 사용 시엔 SageMaker 도메인을 생성해서 사용해야한다.
- studio lab은 JupyterLab IDE를 기반으로 동작하며 무료로 사용할 수 있다.
- Canvas, RStudio


- Canvas도 Studio와 마찬가지로 도메인을 우선 생성해야하며 2개월 간 무료로 사용할 수 있다.
- RStudio도 Studio와 마찬가지로 도메인을 우선 생성해야하며 R과 Python에 대한 워크로드를 제공한다.
2) Domains

- SageMaker 도메인은 연결된 Amazon Elastic File System(Amazon EFS) 볼륨으로 구성된다.
3) SageMaker dashboard
- Images는 Studio 도메인과 동일한 리전에 있는 Amazon ECR의 이미지 경로를 입력한 후 이미지를 만든다
- Lifecycle configurations는 jupyter server app, kernel gateway app를 선택하고 스크립트를 통해 수명주기를 관리한다.
- Search는 속성, 운영자, 값으로 설정해 결과를 도출한다.
4) SageMaker dashboard - Governace
- Model dashboard : SageMaker 콘솔에서 액세스할 수 있는 중앙 집중식 포털로 계정의 모든 모델을 보고 검색하고 탐색할 수 있다.
- Model cards : ML 모델에 대한 중요한 세부 정보를 한 곳에서 문서화
5) SageMaker dashboard - Ground Truth
- Labeling jobs, datasets, Labeling workforces
- Image Classification과 Bounding box, semantic segmentation 등과 같은 label을 선택해 데이터셋에 적용
- 레이블링하는 서버리스 환경
- s3를 통해 레이블링이 필요한 데이터 설정
- private, public 설정을 할 수 있다.
6) SageMaker dashboard - Notebook
- Nodebook instances, Git repositories
- Jupyter lab을 생성시킬 수 있고 관리할 수 있는 Git repository를 연결할 수 있다.
7) SageMaker dashboard - Processing
- Processing jobs : 데이터를 분석하고 기계 학습 모델을 평가하는 솔루션, 실험 단계 동안과 코드가 프로덕션에 배포된 후 Amazon SageMaker Processing API를 사용하여 성능을 평가할 수 있다.
8) SageMaker dashboard - Training
- Algorithms
- XGBoost : Gradient Boosting 알고리즘을 분산환경에서도 실행할 수 있도록 구현해놓은 라이브러리
- Linear Learner : 선형회귀
- KNN : 최근접 이웃 지도 학습 알고리즘
- Factorization Machines : 분류 및 회귀 작업 모두에 사용할 수 있는 범용 지도 학습 알고리즘
- Object2Vec : 모델의 교육과 추론의 기반이 되는 비슷한 단어, 문구, 문장이 있는 애플리케이션에서 사용되는 새로운 지도 학습 알고리즘
- Image Classification : 이미지 분류
- Object Detection : 디지털 이미지와 비디오로 특정한 계열의 시맨틱 객체 인스턴스를 감지
- Semantic Segmentation : 동일한 개체 클래스에 속하는 이미지 부분을 함께 클러스터링하는 작업
- k-means : 주어진 데이터를 k개의 클러스터로 묶는 알고리즘
- DeepAR : Amazon Sagemaker에서 제공하는 forecasting 알고리즘
- Blazing Text : 감정 분석, 기계 번역 등과 같은 많은 다운스트림 자연어 처리 작업에 유용
- MxNet : 신경망을 훈련시키고 디플로이하기 위해 사용되는 오픈 소스 딥 러닝 소프트웨어 프레임워크
- NTM : NTM은 문서의 말뭉치를 통계적 분포를 기준으로 한 단어 그룹이 포함된 주제로 구성하는 데 사용되는 비지도 학습 알고리즘
- LDA : 주어진 문서에 대하여 각 문서에 어떤 주제들이 존재하는지를 서술하는 대한 확률적 토픽 모델 기법 중 하나
- PCA : 차원축소
- Random Cut Forest : RF는 증분식 업데이트가 어렵지만 RCF는 증분식 업데이트가 가능하도록 설계된 알고리즘
- IP Insights : IP 주소를 기반으로 비정상적인 동작과 사용 패턴을 탐지하는 비지도 학습 알고리즘
- Training jobs : 모델, 하이퍼파라미터, 입력데이터, 출력데이터 등에 대한 설정을 할 수 있다.
- Hyperparameter tuning jobs : 사용자가 선택한 알고리즘에 맞는 하이퍼파라미터에 대한 튜닝을 할 수 있다.
9) SageMaker dashboard - Inference
- Compilation jobs, Marketplace model packages, Models, Endpoint configurations, Endpoints, Batch transform jobs, Shadow tests
- ML 모델을 쉽게 배포하여 모든 사용 사례에 대해 최고의 가격 대비 성능으로 예측을 수행할 수 있다. 모든 ML 추론 요구 사항을 충족하는 데 도움이 되는 광범위한 ML 인프라 및 모델 배포 옵션을 제공한다.
10) SageMaker dashboard - Edge Manager
- Get started, Edge packaging jobs, Edge device fleets, Edge devices
- 에지 장치에 대한 모델 관리를 제공하므로 기계 학습 모델을 최적화, 보호, 모니터링 및 유지할 수 있다.
11) Augmented AI
- Human review workflows, Worker task templates, Human review workforces
- 인적 검토 시스템을 구축하거나 검토자를 관리하는 것에 대한 부담을 줄여주고 모든 개발자에게 ML 예측에 대한 인적 검토를 제공하는 서비스
12) AWS Marketplace
- Model packages, Algorithms, AWS Data Exchange, All products
- SageMaker는 AWS Marketplace와 통합되어 개발자가 본인의 사전 학습된 모델을 이용하는 다른 사용자에게 비용을 청구할 수 있다
3. SageMaker 실습
1) Notbook Instance 생성
- Name : demo-notebook-1
- instance type : ml.t2.medium
- IAM role 생성
- Jupyter lab 접근
from sklearn import linear_model
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
x = np.array([0.1,0.4,0.7,1.2,1.3,1.7,2.2,2.8,3.0,4.0,4.3,4.4,4.9]).reshape(-1,1)
y = np.array([0.5,0.9,1.1,1.5,1.5,2.0,2.2,2.8,2.7,3.0,3.5,3.7,3.9]).reshape(-1,1)
reg = linear_model.LinearRegression()
reg.fit(x,y)
reg.coef_ # theta 1 : array([[0.67129519]])
reg.intercept_ # theta 0 : array([0.65306531])
plt.figure(figsize=(10,8))
plt.title('$L_1$ and $L_2$ Regression', fontsize =15)
plt.xlabel('X', fontsize = 15)
plt.ylabel('Y', fontsize = 15)
plt.plot(x,y,'ko',label="data")
# sklearn은 xp, reg.predict(xp)의 xp를 기입하지 않아도 실행된다.
plt.plot(xp, reg.predict(xp), 'r', linewidth = 2, label = "regression")
plt.legend(fontsize = 15)
plt.axis('equal')
plt.xlim([0,5])
plt.grid(alpha=0.3)
plt.show()
2) studio
<s3 버킷 생성>
- kaggle에서 다운로드
- 데이터 업로드
- input : csv
- out 폴서 생성
<studio 생성>
- 도메인 생성

- 이름 입력
- vpc 설정
- studio
- role 설정
- 접속
- automl선택
- new autopilot 생성
- 이름
- s3 버킷 입력
- dataset file name : train.csv 넣기
- target : label
- s3 bucket name : output버킷 이름 (방금 생성한 s3 버킷) => output 폴더
- machine learning problem : multiclass classification
- objective metric : accuracy
4. MLOps 및 Data Pipeline 실습 공부

- DevOps, Solution Architect, MLOps 등에 대한 역량을 키우기 위해선 Data Pipeline을 최적의 조건으로 따지는 것도 좋지만 가트너를 기반으로해서 시장성이 좋은 여러가지 서비스와 툴을 최대한 사용하여 해결해 보는 것도 좋은 공부가 될 것이다.
- 처음엔 가벼운 데이터 셋으로 시도해보고 그림에 기입하지 않았지만 AWS Redshift, AWS Glue 등 다양한 솔루션을 추가해 심화 학습을 진행할 수 있다.

특히 데이터 시각화를 담당하는 Tableau는 최근 Gartner의 Business intelligence Platforms 부문에서 Microsoft 다음으로 좋은 성적을 거뒀고 salesforce가 협업툴인 "Slack" 또한 보유하고 있기 때문에 상호간 연계 또 기대해 볼만 하다.
5. 클라우드와 MSA 환경에서의 AI Insight

https://proceedings.neurips.cc/paper/2015/file/86df7dcfd896fcaf2674f757a2463eba-Paper.pdf
- 실제 AI에서의 코딩과 모델링이 시행되는 기간 및 범위는 굉장이 작다.
- 기업들이 모델링보다 데이터의 자체의 퀄리티가 중요하다고 판단하고 있다. 아래 그래프를 보면 단순 데이터 부족 문제가 존재하지만 데이터 품질도 적절하지 않아 AI를 채택하지 못하는 회사가 그 중 18%나 된다.
- 현실은 위와 같은 시스템을 가지고 있기 때문에 ML 기반 파이프라인과 인프라가 중요해졌고 MLOps의 중요성을 보여준다.
- 다수의 회사가 위와 같은 솔루션을 채택하지 못하는 문제를 겪고 있다
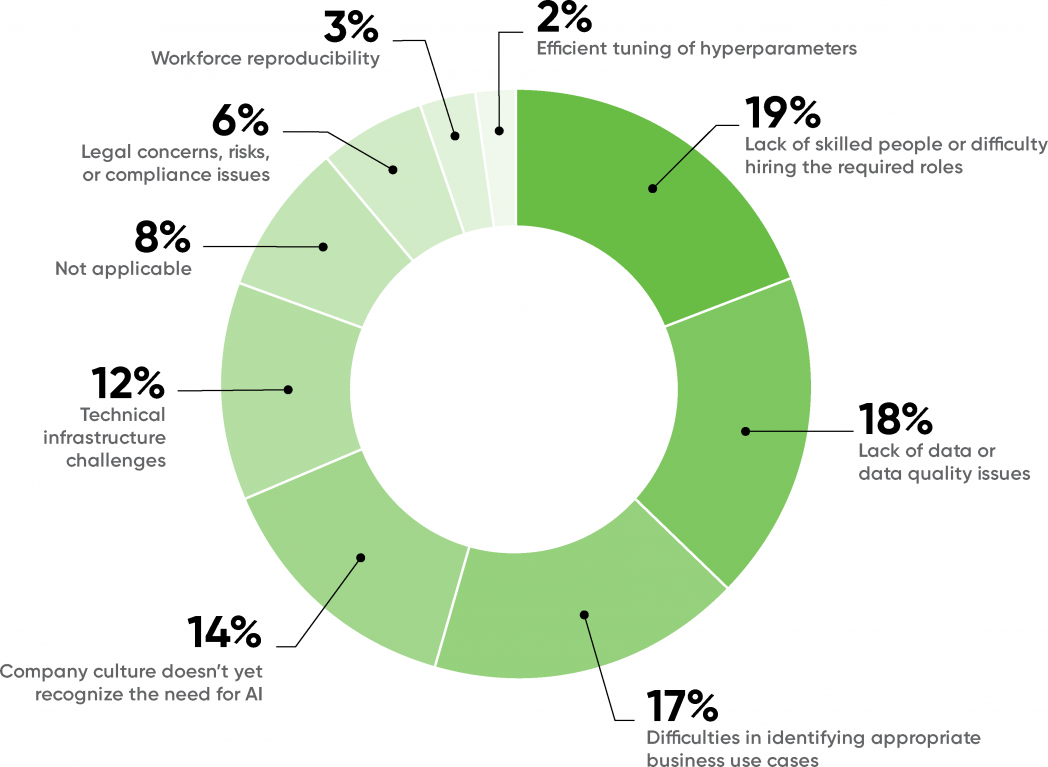

19% : 숙련된 사람이 부족하거나 필요한 역할을 고용하는 데 어려움
18% : 데이터 부족 또는 데이터 품질 문제
17% : 적절한 비즈니스 사용 사례 식별의 어려움
14% : 기업 문화는 아직 AI의 필요성을 인식하고 있지 않음
- 데이터사이언티스트는 MSA 쿠버네티스 환경에서 최적의 머신러닝 딥러닝 학습을 해야하는 상황에 직면해 연구와 프로덕션을 같이 진행할 수 밖에 없다.
- kubeflow와 같은 쿠버네티스 환경 머신러닝 파이프라인 솔루션이 존재하지만 데이터사이언티스트가 쿠버네티스 환경까지 이해해야하는 어려움이 아직 존재하고 지속적인 통합, 지속적인 배포, 지속적인 학습을 수행해야하는 DevOps와 AI에 대한 역량이 필요하기 때문이다.
- 이로인해 숙련된 사람이 적고 적절한 비즈니스 사례를 찾기 어려운 상태이다.
- kubeflow 이상의 편의성을 제공하고 데이터사이언티스트가 쿠버네티스를 이해하지 못하더라도 쉽게 파이프라인을 구축할 수 있는 오픈소스가 출시된다면 수요가 급증할 수 있다
< 컨퍼런스 참고 내용 >
<딥러닝 적용 시 문제였던 점>
1. 데이터가 정제화되지 않은 문제
=> data centric ai
2. 복잡도 증가
=> MLOps기반 ml플랫폼 활용
3. 지도학습은 다량의 이미지 데이터 필요
=> 지도학습 외 저비용 학습 기법 사용
4. 반복적인 재학습이 필요하다는 문제
=> 점진적 학습을 위한 ml 플랫폼 경험 축적 및 운영 커스터마이징
5. 데이터 접근 제한성
=> 현장 데이터 기반 end to end vision ai 응용 개발